
10 Ene evolucion del mantenimiento hasta el momento actual: «data analytics & machine learning
El presente articulo no pretende ser un estudio teórico ni profundizar en cada uno de los conceptos que se exponen. Pero si ayudar a las personas interesadas y los técnicos involucrados en mantenimiento a analizar, de forma amena y sencilla, el pasado y presente del mantenimiento y sus conceptos básicos.
¿Qué es el mantenimiento?
Las podemos definir como aquellas pautas de conservación y mejora que se aplican durante el ciclo de vida de un producto, equipo o conjuntos de equipos unidos para producir un fin. En su forma mas simple, la de un solo producto aislado, un cuchillo, por ejemplo, nos referiremos a su limpieza y afilado. El siguiente paso a este producto aislado, al que poco nos vamos a referir en este artículo, podía ser el de una cortadora de césped, en la que tenemos motor, cuchillas, arranque, interruptores etc. Pero lo que nos va a dar sin duda mas juego para nuestro artículo, son los sistemas más complejos. Imaginemos un coche, en el que tenemos una multitud de piezas y de componentes, todos con una finalidad: Desplazarnos seguros durante un periodo determinado de KM con un consumo razonable.
Pero en su expresión mas compleja, e interesante para exponer lo que vendrá a continuación, están los sistemas complejos: Por ejemplo, una refinería de petróleo. En una refinería tenemos una gran variedad de equipos, unos más sencillos como motores y bombas, otros más complejos como turbinas, reactores químicos, algo mucho mas complejo en su comportamiento. Contando además con infinidad de tuberías, cuadros eléctricos, cables, etc. Además, en estos sistemas la finalidad es mucho más compleja que en el coche: Recibimos petróleo de diversas calidades y producimos una variedad de productos químicos que se producen en la destilación del petróleo y procesos posteriores.
¿Cuál es el objetivo del mantenimiento?
Obviamente a cualquiera se le ocurre, pensando en nuestros vehículos, que este objetivo será que cumpla su función sin incidentes no programados, para lo cual deberemos cambiar el aceite, las pastillas, etc. Para ello el fabricante establece unas pautas, que, si hay suerte, nos evitaran quedarnos tirados o tener un accidente.
En general, cuando vamos a un sistema mas complejo aun, una refinería, por ejemplo, los objetivos son semejantes. Pasemos a entrar en más detalle:
- Coste: Los costes de parada de una planta son altísimos. Si la parada no es parcial, pero es total, aun mas grandes. El no hacer preventivo (cambio aceite en motores, por ejemplo) hará que, si el ciclo de vida de la planta son 40 años, en ese tiempo debamos comprar mas motores que los necesarios, o hacer más reparaciones.
- Seguridad: cada vez las empresas se preocupan mas por la seguridad y el impacto en el medioambiente. Es al final coste, social en este caso. Por ello la seguridad y el impacto ambiental es clave hoy en día. Llevado al caso de nuestro vehículo, no cambiar las pastillas de freno es menos costoso, pero no es seguro. Si nuestro vehículo contamina, no deja de llevarnos donde queremos, pero impactamos el medio ambiente.
Es frecuente la creencia de que aumentar la seguridad nos llevara a sobrecoste. No debe ser así, si nuestra estrategia de mantenimiento está bien entretejida, como veremos más adelante
¿Cuáles son los tipos de mantenimiento básicos?
Durante muchos años los equipos se han mantenido jugando con dos estrategias complementarias:
Correctivo: Es decir, si se rompe un manguito de mi vehículo y tengo suerte de que no se recaliente y genere mas problemas al vehículo, lo cambio y resuelto.
Preventivo: Posiblemente el fabricante no previo que este manguito se fuese a romper durante la vida esperada del vehículo. Y por ello no habíamos hecho lo que se denomina preventivo: Cambiarlo antes que se produzca la rotura. Este suele ser el caso de correas de distribución no metálicas en vehículos, o lo que todo el mundo conoce, cambiar el aceite del motor antes de que envejezca y afecte a la vida media del mismo.
Estos dos tipos de mantenimiento han constituido el 90% de la estrategia que ha generado las pautas de mantenimiento de la industria. Y durante muchos años, el correctivo ha sido el predominante. Porque el preventivo, aunque no parezca lo lógico, se ha descuidado en las plantas industriales. Porque no pensemos que preventivo es solo cambiar aceites. Limpieza de filtros, polvo en cuadros eléctricos, pila de soporte ante fallo de energía gastada en un autómata programable de control, nos pueden terminar parando toda una planta.
De lo anterior podemos concluir como con otros tres factores ligados al mantenimiento, al coste y la seguridad:
1 Gestión de stock de piezas de recambio: Hay muchas implicaciones que hacen un mantenimiento, sea cual sea el tipo, funcione con eficacia. Entre ellas la gestión de intervenciones, las ordenes de mantenimiento que se suelen gestionar desde un sistema informático, la gestión de compra y almacenamiento de piezas que puedan ser criticas…No vamos a entrar en este articulo en el detalle de como se gestiona. No olvidemos que hay dos normas bajo el paraguas de la ISO 5500 que tratan estos temas y su certificación en cuanto a procesos. Pero es obvio que la eficacia de estos procesos es clave en la reducción de costes. Cuando tenemos un equipo que falla inesperadamente, pueden ocurrir dos cosas, que sea Crítico o no, y ello debe afectar a nuestra política de compras y estocaje:
- Que sea crítico y afecte a la producción
- Que esta consideración la considerase ya el que diseño el proceso, y que haya otro redundante (que haga lo mismo)
- Que lo tengamos en stock en la planta, y que podamos dar orden de reemplazo inmediata. Esto seria extremadamente necesario si no hay uno redundante en el proceso
- Que haya que comprarlo. Aquí se manejan dos estrategias. Si sabemos que el componente es crítico por como afecta a la parada de la planta, lo mejor es que nosotros lo estoquemos o que tengamos un contrato con el suministrador en el que el nos asegura el estocaje en su casa, con entrega 24H X 7 días. En caso contrario, mas vale que empecemos a pensar en mejorar nuestra estrategia.
- Que no sea crítico:
En este caso es posible que hasta podamos esperar a un suministro normal de repuestos.
No entraremos en este detalle, como no lo hicimos en el caso de los sistemas de gestión: Solo mencionar que compras, junto a mantenimiento, debe asegurar la disponibilidad de stock en casa o en el suministrador de componentes críticos. En estos casos se suele hablar de compras estratégicas y acuerdos marcos con suministradores que son críticos para nuestra produccion. En el caso de piezas no críticas, lo mejor es contar con suministradores alternativos donde buscar los mejores plazos de entrega. Luego en este articulo abundaremos en lo que representa esta criticidad, pero llevando la a lo que sería la probabilidad de fallo particular o general de la planta.
2 Control de tiempos de operación y estado de los equipos:
Si la gestión de stock encajaba mas con el correctivo, esta parte que vamos a describir ahora encaja más con el preventivo. Desde hace mucho tiempo, y mas aun desde los años 70 y la aparición de los primeros ordenadores dedicados para la industria (Control distribuido, autómatas), y generalizado con la entrada de los PCs en el 80, y el consiguiente abaratamiento de la electrónica, las plantas disponen de muchísimos sensores que nos proporcionan infinidad de datos de como opera la planta, estados por los que pasan los equipos, tiempos de uso, parámetros como vibraciones, temperaturas, etc. Luego abordaremos el tema de los datos cuando hablemos como las modernas metodologías de análisis de datos y “Machine learning” (aprendizaje de las maquinas). Pero entendamos por ahora, que no podríamos hacer preventivo sin poder usar sensores que nos marquen tiempos o condiciones (desgaste de piezas, por ejemplo, como las pastillas del coche) que nos indiquen que ya debemos lanzar operaciones de mantenimiento. En caso de no existir estos controles, solo podríamos hacer inspecciones visuales programadas.
3 Mejora de la ingeniería de Diseño:
El diseño del ciclo de vida del producto o de nuestra planta, en caso de mayor complejidad, es algo que debe empezar por el diseño. Por solo poner el ejemplo más sencillo, el de la ubicación de equipos. imaginemos que tenemos un sistema de análisis químico al que tenemos que limpiar los filtros y que esta en lo alto de una torre donde prácticamente no hay espacio para caminar. Una operación sencilla podría ser excesivamente larga cara y peligrosa. Pero hay otros muchos factores que se deben tener en cuenta en el diseño, además de la ubicación. Unos obvios como el anterior, y otros no tan obvios. Antes veíamos como las ingenierías que diseñan plantas colocan sistemas redundantes en los equipos que afectan al coste o la seguridad. La mejora del diseño solo es efectiva si se dispone de históricos de plantas o equipos similares a tener en cuenta. De como han fallado, como se habían mantenido, etc. Esto nos lleva a dos conceptos que ya hemos esbozado y que concluiremos más tarde:
- Análisis probabilístico de fallos (PRA por sus siglas en Ingles) y estudios que las ingenierías ya realizan desde hace tiempo a través de lo aplicado a diseño de aviones y plantas potencialmente peligrosas, como Nucleares. Con esta metodología se logra que la probabilidad de una parada o fallo de seguridad graves no sea probable, aplicando el mantenimiento adecuado.
- Sensores adecuados para poder adquirir los valores históricos de la planta, no solo para la operación, sino para el mantenimiento posterior. Y como veremos, hoy buscamos además que los datos nos permitan modelizar el proceso de envejecimiento y fallo de los equipos, especialmente los complejos, y predecir cuándo fallaran.
Aparte de estos, que serán objeto de análisis posterior, las ingenierías deben de realizar otro tipo análisis para definir sus diseños definitivos. Algunos de ellos:
- Estandarización: Agrupamiento de tipos, marcas, calibres y todo aquello que permita la reducción del stock posterior y simplifique la gestión de compras y la disponibilidad de repuestos.
- Modelado en 3D: Posibilidad de “walk trough” (paseo virtual por la planta), en el que se enlazan componentes del modelo con sus hojas de datos originales, a los que el mantenedor de la planta añade datos históricos de funcionamiento y cambio de diseño introducidos.
Podríamos citar mas estrategias del diseño que contribuyen a lograr un ciclo de vida mas fiable, barato y seguro de los sistemas complejos. Un gran ejemplo, diferencial en el mundo industrial, son los vehículos que mencionamos antes en la introducción y que son un gran modelo de evolución. Ello es debido a que la fase de ingeniería de los vehículos es primordial en este tipo de fabricantes, e invierten mucho más dinero que otros usuarios de plantas que encargan la ingeniería a terceros con costes más acotados. Son ellos mismos los que realizan los diseños junto con los estilistas y los fabricantes de líneas de producción. Todo en una sintonía perfecta, enfocada a lograr la mayor eficiencia en fases de fabricación y la mejor respuesta en duración y seguridad para los vehículos que producen. Hace años no se podía soñar en la durabilidad actual de estos equipos, que se usan por personas diferentes en condiciones a veces extremas. Sin olvidar los sistemas de seguridad, que llegan hoy hasta la conducción autónoma y la evasión de colisiones. Son verdaderos ordenadores con ruedas. Cuentan con miles de sensores en algunos casos, y varios robustos ordenadores que se ocupan, cada uno, de diferentes funciones del vehículo, y que procesan y se coordinan miles de veces por segundo para tomar las mejores decisiones de operación, registrar valores, y definir no solo pautas de mantenimiento, sino de aprender del propio vehículo (“Machine Learning”). Posiblemente, junto los aviones, son los equipos donde el control de operación y mantenimiento es tan sofisticado, siendo incluso capaces de conexión remota con los fabricantes.
¿Qué es el mantenimiento predictivo?
Es tan obvio como delata su propio nombre, y ya lo hemos esbozado en párrafos anteriores: Hagamos algo en nuestros equipos antes de que fallen, siguiendo indicios, patrones, modelos o alertas que nos ayuden a evitar el correctivo. No lo confundamos con el preventivo, mediante el cual, según el tiempo, u otra forma de detectar desgaste directo, nos lleva a realizar tareas (cambio aceite, pastillas del freno, tensado de correas. etc.)
El mantenimiento predictivo es la estrella de nuestra estrategia. Pero sin duda será el mas sofisticado y el que nos requerirá mayor inversión, pero nos producirá los mayores ahorros. Por ello lo dedicaremos a aquellos equipos que intervengan de forma mas directa en grandes paradas de equipos o de una planta al completo.
A partir de ahora entraremos en detalle de los que seria nuestra estrategia para desarrollar modelos de mantenimiento predictivo. Los otros dos tipos ya los tratamos anteriormente y quedan ya descritos. Finalmente veremos como se puede conjugar todo en su conjunto.
CALS (Computer Aided Logistics Support)
Sin querer entrar en detalle de esta tecnología que por los años 80 y 90 ya desarrollaba el departamento de defensa americano, si nos gustaría dar una breve introducción al objetivo que persigue. Los equipos que compra defensa están sometidos a condiciones muy duras de funcionamiento y deben de estar diseñados para unas condiciones de trabajo muy severas. Desde el diseño, la fabricación, operación y reciclaje de los equipos (ciclo total de vida), pretende tener un monitoreo y seguimiento constante de todos los parámetros que intervienen en estas fases. Y para ello, y dado que en esta época los ordenadores eran mas asequibles, todo ello se seguiría mediante programa de ordenador y grandes bases de datos. Todo ello compartido por los diferentes actores que intervienen en cada parte del ciclo de vida, desde fabricantes a mantenedores. No es extraño que, dado el volumen de inversión en defensa, esta tecnología se pretendiese poner en marcha. Muchos departamentos de defensa han tratado de algún modo de implementar modelos semejantes, pero sin la amplitud pretendida. Durante la guerra de los Balcanes por ejemplo, muchos carros y vehículos todo terreno fueron abandonados en el terreno de operaciones, sin que se registraran sus condiciones de operación, fallos, causas de envejecimiento prematuro etc.
El motivo de citarlo es porque dieron en aquellos años mucha relevancia a dos tipos de mantenimiento preventivo que describimos a continuación y que hoy están vigentes
Mantenimiento basado en la fiabilidad y la condición
En Ingles “Reliability Based Maintenance (RBM)” y “Condition Based Maintenance (CBM)”, son dos estrategias para organizar el mantenimiento preventive, y que nos proporcionan rutinas de control y de intervención mucho mas avanzadas que las ya descritas. Son complementarias, y llevadas a un extremo, pueden convertirse en el nexo de unión de rutinas elaboradas que nos permitan llegar a un mantenimiento bien estructurado y del tipo que denominamos arriba predictivo.
El RBM nació en la década de los 60 del siglo XX en la aeronáutica. Y trataba de aplicar calculo probabilístico. No es el objetivo de este articulo entrar en detalles de esta metodología, de como se hacen los cálculos estadísticos, ni como puede llegarse a combinar con el resto de las estrategias de mantenimiento. Pero si el dar una visión de como se aplica y que resultados da.
Ya dijimos que es muy importante en mantenimiento el identificar componentes críticos. Denominados así poque contribuyen de manera muy directa a la parada parcial o total de equipos, sistemas complejos o planta completa. Puede parecer obvio identificar que equipos pueden fallar si conocemos la planta. Sin embargo, a veces encontramos relés o interruptores, y otros elementos ocultos en los armarios de control que intervienen en el funcionamiento de equipos mayores. Este es solo un ejemplo de cómo, sin un análisis funcional exhaustivo de cada sistema, es imposible saber cual son exactamente esos componentes críticos.
Así que lo primero que debemos hacer, si queremos aplicar rutinas de mantenimiento basadas en esta estrategia, es realizar un análisis funcional de los sistemas de nuestra planta. Un análisis funcional debe identificar, describir y analizar como cada componente de un sistema interviene en el posible fallo del mismo. Desde los elementos de control y mando como decíamos, a los elementos mecánicos como motores, bombas y equipos más complejos.
Esta sería la parte analítica del ejercicio. Puede extenderse a un sistema o puede ampliarse a toda una planta, con mayor o menor detalle. El siguiente paso sería el cálculo probabilístico.
Este calculo se realiza en base a una metodología denominada FMEA (“Failure mode and Effects Analysis”). Para aplicar esta metodología, usaremos los valores de probabilidad de fallo de los componentes discretos que ya hemos identificado en el paso anterior. Los fabricantes nos indican, por ejemplo, el número de maniobras que un relé realizara antes de fallar. Combinando como interviene cada elemento y su tasa de fallo, podemos obtener la probabilidad de fallo de un sistema completo a analizar.
Este tipo de estrategias suelen combinar la probabilidad de fallo con los costes de parada inducidos en el caso de fallo un sistema o subsistema. Por ello es fundamental que, si abordamos una estrategia sofisticada como esta, seamos capaces de conocer cuanto nos cuesta parar nuestra planta, o una parte de ella, y las implicaciones económicas que tienen. Es frecuente ver empresas que aseguran tenerlos, pero que llegado el caso de tener que usarse, no son conocidos de una forma estructurada
Dicho de una forma sencilla y vaga, este el proceso y sus resultados. Como ejemplo de aplicación tenemos el denominado análisis probabilísticos de riesgos (PRA), que se levan a cabo en Centrales Nucleares y que nos indican la probabilidad de fusión del núcleo en caso de accidentes y que ya comentábamos antes cuando hablamos de factores de diseño.
Si aplicamos este análisis, seremos capaces de conocer posibles criticidades ocultas y además estructurar nuestro mantenimiento de una forma óptima. El grado de profundidad nos lo dará el equilibrio entre inversión y ahorro en coste. Como dijo el Filosofo Frances Voltaire, lo perfecto es enemigo de lo bueno. Y en este punto del articulo ya hemos llegado a un grado de complejidad en la estructuración de estrategias, que conviene tenerlo en cuenta.
Un factor decisivo a la hora de hacer estudios de RBM es el contar con documentación y planos actualizados de nuestros sistemas. Cuando por ejemplo en una planta nos estrega la ingeniería los sistemas, adjunto a ellos nos llegan hojas de datos, planos y esquemáticos. Esta documentación se denomina “as built” es decir, según construido Es interesante que estos se mantengan al día y que las hojas de datos de componentes tengan datos de sus ratios de fallo. Estos dos factores, que parecen obvios, no lo son. Y lo mas normal es que las instalaciones al cabo de los años sufran modificaciones menores no programadas, a veces impuestas por el correctivo, y que los planos estén desfasados. Y no menos extraño que se canibalicen equipos reemplazados para extraerles piezas de recambio, o que se sustituyan piezas en los sistemas que no cumplen con las especificaciones iniciales.
En conclusión, estamos definiendo unas estrategias muy elevadas y que pueden ser complejas, pero lo básico, desde quitar el polvo, hasta conocer el estado de nuestros equipos, a veces se olvida.
El mantenimiento basado en la condición es otra estrategia más, que combina con lo anteriormente descrito y que ya esbozamos antes. Y que nos puede dar en su esencia más simple información para el preventivo, y en su máxima expresión llevarnos al más fino ajuste de lo que sería un predictivo (“Machine Learning”)
Ya mencionamos que, con la aparición de los ordenadores asequibles, los integradores de sistemas de control comenzaron a ofrecer a los clientes sistemas de supervisión (SCADAS) con innumerables pantallas y medidas de sus sistemas. Se llego a cobrar por su número, sin saber muy bien que se iba a hacer con información a veces redundante en diversas pantallas e innumerable numero de señales.
Es a lo largo de este siglo XXI cuando empezamos ver en algunas multinacionales de elite interés por aplicar el histórico de datos de sus sistemas productivos, no solo en el mantenimiento, sino también en sus operaciones. Ello es debido a que se utilizan en operación capas en los sistemas de control y supervisión de ayuda a los operadores y de filtrado de alarmas, etc. Y al mismo tiempo se empieza a pensar cómo utilizar esa ingente cantidad de datos para analizar como se produjo la secuencia de eventos antes de un fallo y estudiar que fallo primero y quien desencadeno la parada final.
Por otro lado, los fabricantes de sistema supercríticos como las turbinas empiezan a vender junto a ellas sistema de detección predictiva de posibles fallos. Se detectan temperaturas y vibraciones en cojinetes y, por primera vez, se ensayan algoritmos de predicción. Es decir, no solo observamos la condición de funcionamiento de un equipo durante su ciclo de vida, sino que además el ordenador es capaz de determinar el momento en que la maquina esta reproduciendo un patrón reconocido como precursor de un fallo fatal.
Con lo anterior, y lo que ya hemos descrito en este artículo, nos podemos hacer cargo de hasta donde llega la estrategia de mantenimiento basado en la condición: No es ni mas ni menos que utilizar sensores y el registro de datos para determinar una pauta de mantenimiento y así evitar un fallo inesperado. Lo mas sencillo ya lo vimos, contar el numero de horas o de maniobras de un equipo y determinar cuando, estadísticamente, le queda de vida útil. Esto que es lo mas sencillo, si se hiciese en combinación con criterios de fiabilidad y criticidad, ya nos ahorraría muchos costes. Hay una pauta de mantenimiento muy sencillita: Cuando un elemento critico llega a un numero de maniobras o tiempo de vida aun muy seguro, se puede rotar a una función similar en otra posición no critica en el mismo o diferente sistema, y colocar uno nuevo en su lugar. De esta forma el elemento en cuestión podría esperar el correctivo en esa nueva posición, sin producir un fallo fatal.
El análisis de la condición de trabajo, su ciclo de vida y estimación de vida remanente de los componentes de un sistema o del comportamiento de un sistema critico completo como una turbina, reactor, etc. admite muchas aproximaciones a diferentes niveles.
Hoy en día la inteligencia artificial, técnicas de análisis de datos, Machine Lerning etc. son capaces de usar variables que se pueden ir recolectando durante el funcionamiento de los equipos y establecer un modelo y definir patrones de fallo. Posiblemente muchos de nosotros hemos visto como muchos operadores de sistemas y mantenedores expertos, que han puesto sus ojos sobre sus equipos durante años, son capaces de intuir cuando una maquina o sistema va a fallar. A veces sin que puedan fundamentarlo más que en su experiencia. Y es que nuestro cerebro es una maquina muy poderosa que es capaz de generar patrones con facilidad, si se le aportan medidas precisas. Y de recordarlas y procesarlas. Esto es lo que hoy en día hacen los ordenadores y los aplicativos que imitan este comportamiento. Pero dejaremos eso para el final de este articulo
“Data Analytics & Machine Learning”, , como estrategia avanzada en el mantenimiento predictivo.
Llegamos por fin a la parte que hemos ido aplazando durante todo el artículo, pero que es el top de la pirámide del mantenimiento, aunque quizá deba colocarse en la base, ya que puede englobarlo todo, siendo el patrón que nos de luz a como concebir nuestra estrategia de mantenimiento.
Hemos comentado como el coste de los ordenadores primero, y el abaratamiento de la electrónica, nos han proporcionado inmensas cantidades de datos de nuestros sistemas. Hoy en día además tenemos herramientas que, cargadas en un ordenador de uso normal, nos permiten análisis de datos y extracción de correlaciones en minutos. Todo está ahí disponible, ya desde hace tiempo. No es hasta nuestros días en la segunda década del siglo XXI donde se le esta dando mas relevancia: Big Data, Minería de datos, Análisis de datos y aprendizaje de las maquinas (una parte de la Inteligencia Artificial que ya se comenzaba a definir el siglo pasado. Ya no son solo las grandes empresas las que quieren usar estas técnicas, porque seguramente se han generalizado, son mas accesibles, es más fácil ver los retornos a la inversión, y estas inversiones son mas pequeñas. Y por que no, esta de moda. Hoy el Internet de la cosas es un hecho, “Industry 4.0 “es un standard que muchos conocemos y los sensores basados en Internet permite capturar muchas mas variables a menor coste.
Vamos a ver, conectando con lo visto hasta ahora, como nuestra estrategia de mantenimiento puede enriquecerse de ello.
Imaginemos un ejemplo sencillo, una bomba que impulsa liquido acoplada a un motor eléctrico, con todos sus automatismos de protección y maniobra. Podría ser que no fuese critica y que su fallo no causara mayor coste que el de la reparación. En ese caso hemos visto que no muchos años atrás su mantenimiento podría ser correctivo.
Aun así, esto no seria muy elegante, y al menos debíamos hacer un preventivo con algo de basado en la condición, si fuera posible, o al menos de inspección visual. Ver si vibra, oír cojinetes, temperaturas engrase y aceites…limpiar automatismos y revisar su estado. Si nuestro programa de preventivo es adecuado, evitaremos fallos costosos en si mismos, aunque no haya consecuencias
Aun mas elegante es contar con monitorización por poco coste. Hoy en día hay sensores que usan redes Lorawan, Wireless industrial en algún standard, o que se conectan a internet y que nos dan temperaturas y vibraciones y que se pueden adherir magnéticamente. Con estas medidas podemos establecer alertas para hacer inspecciones o reemplazos parciales
Si es un servicio critico en el que, como ejemplo, su fallo desencadena el de una torre de destilación, con un coste de parada X, seguramente nos hayamos planteado hacer un análisis funcional de sus subsistemas y tengamos identificados posibles relés o elementos discretos en la cadena que puedan producir un fallo o bien fatal, o bien difícil de identificar a priori. No olvidemos que la identificación de la raíz del fallo (“root analysis”) lleva tiempo si el ejercicio no se ha hecho con anterioridad. En este caso, habiendo aplicado criterios de fiabilidad. De esta forma, y si este subsistema no cuenta con uno redundante o funciona en paralelo con otro del 100% (sería una decisión de diseño), estaría bien monitorizado y se deberían aplicar patrones mas estrictos que en el caso anterior. Deberíamos tener los sensores adecuados que nos dieran un registro histórico de cómo han evolucionado en funcionamiento normal, su degradación durante el envejecimiento normal y acelerado antes del fallo.
Y acabamos de entrar en lo que seria la parte de análisis de datos. Aunque este caso es muy sencillo, y seguramente los patrones serian obvios, existe una metodología y herramientas para tratar estos datos, que es lo que constituye la tecnología de “Data Analytics”, mediante los cuales podemos descubrir patrones de comportamiento en funcionamiento normal, definir como es la degradación normal y descubrir un cambio de patrón que nos va a denotar un fallo en un tiempo T.
La magia en la búsqueda de estos patrones y como aplicarlos es que nos deja lugar a la creatividad a costes relativamente bajos. Imaginemos que tenemos varios grupos de motobombas similares funcionando en nuestra planta, que deberían estar dando patrones similares. Es muy sencillo hoy en día dotarlas de algunos sensores de instalación inmediata y llevarlos al repositorio de datos (data Lake) de la compañía, o al cloud, y allí identificar patrones y desviaciones entre equipos similares.
Hemos puesto un ejemplo muy sencillo, pero imaginemos equipos complejos electro químico mecánicos, donde interviene la físico química y la mecánica y la electricidad, en el que las funciones de transferencia (lo que recibe y lo que produce) son muy complejas, así como su control. Con numerosas etapas con presiones y temperaturas. Y que su fallo quizá nos pare nuestra planta completamente. En este caso ni el mejor de los operadores sería capaz de intuir lo que un análisis de datos y metodología de correlación matemática de los mismos puede obtener. Hoy en día se empieza a obtener éxitos importantes en plantas químicas, por ejemplo, para identificar las causas mediante las cuales tenemos una rotura de la fibra que estamos produciendo (Nylon, por ejemplo). Esa rotura supone que se rompe un proceso que es continuo. Parar, resolver, volver a poner en marcha…un coste muy alto. Ya no solo hablamos de mantenimiento, sino de operación. Nuestras conclusiones nos pueden llevar a mantener las condiciones de operación entre unos valores determinados o quizá correlaciones estudiadas entre variable como temperaturas y presiones, si fuera de un marco de funcionamiento corremos el riesgo de producirnos esa parada.
Finalmente, en este tipo complejo de casos, podemos encontrarnos con la necesidad de:
- Poner mas sensores porque no somos capaces de descubrir patrones, pero identificamos esa carencia
- Forzar el proceso para producir intencionadamente zonas de funcionamiento criticas y obtener nuevas correlaciones entre las variables
Pero lo cierto es que esta metodología, si se pone en marcha con datos existentes, aun sin forzar, y si además se tienen históricos de valores antes del fallo, suelen dar buenos resultados.
Hasta hace no mucho tiempo, muchos de estos patrones quedaban en la mente de los operadores, pero no estructurados, ni mucho menos con posibilidad de producir avisos a tiempo. Además, las personas se jubilan y vienen nuevas, pero nosotros queremos que esto no afecte a nuestros procesos. Al igual que el cerebro humano descubre patrones (análisis de datos), y es capaz además de recabar experiencia y aprender de lo que observa en los procesos, hay una parte de la inteligencia artificial que pretende hacer lo mismo: “Machine Learning”
No estamos descubriendo nada nuevo, tan solo dinamizando en el tiempo lo que hemos comentado para la analítica de datos. Imaginemos que nuestro ordenador, mediante programas de aprendizaje que se instalan en él, esta de forma permanente vigilando a nuestro sistema y siguiendo la evolución de los parámetros. Tanto si disponemos de equipos en los que conocemos ya su forma de fallo (supervisados), como en los que es desconocido como lo hacen (no supervisados), esta tecnología será capaz de encontrar correlaciones, patrones, algoritmos y modelos de comportamiento, y además actualizarlos según la operación de los equipos.
No nos olvidemos algo que se nos suele pasar: Lo mas importante es disponer de datos que sean fiables y que estén bien etiquetados. Los resultados serán mas rápidos. Pero existen métodos computacionales que permiten tratar datos con incertidumbre. Hasta ahí podemos llegar. Pero siempre debemos ser capaces de identificar el nivel de incertidumbre para acotar también la incertidumbre de los resultados, que será de menor cuantía.
Un forma grafica de verlo
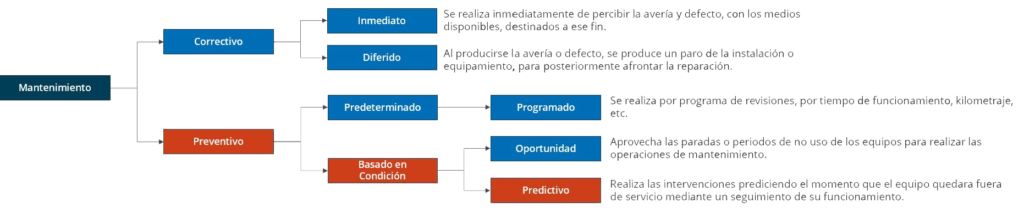
Conclusión final
Se han expuesto de forma somera y si entrar en detalles, diversas estrategias que debían tenerse en cuenta en la definición de nuestro plan de mantenimiento.
Ninguna es mejor que la otra, y todas deben combinarse con dos objetivos que ya dijimos y recordamos
- Eficacia y reducción de coste
- Seguridad
Durante muchos años muchas empresas, aun contando con información e históricos suficientes, no han estimado oportuno realizar un mantenimiento mas estructurado y se han entregado sin remedio al correctivo. Muchas veces a imperado el miedo a unos costes exagerados. También la creencia de que nuestro mantenimiento es el mejor: “Mi equipo técnico es excelente y sabe lo que hace”. Lo cual es probable que sea así, pero seguro que mejorable.
Buscar el equilibrio coste e inversión es un ejercicio hoy en día obligatorio. Despreciar la valiosa información histórica que sin duda tenemos es malgastar dinero. Los sensores son tan baratos que nos podemos permitir añadir mas para poder predecir mejor.
Hay Consultores asequibles que nos pueden ayudar a implementar paso a paso estrategias de predicción avanzadas que nos permitan evitar fallos fatales
No nos olvidemos de la seguridad. Nuestras plantas deben cumplir la normativa. Suele disponer de sistemas que vigilan presiones y temperaturas, que nos alarman antes de una rotura fatal que afecte a las personas. Además, se suele instalar en varios pasos, alarma y actuación, como el caso de válvulas de alivio de presión, discos de ruptura, etc. Pero no olvidemos que se calcularon cuando se diseñaron los sistemas. Que no se volvieron a considerar estos escalones, que han podido variar con el uso y envejecimiento de los sistemas, o que incluso pueden estar inoperativas. ¿Extraño no? Pero sucede: no hay mas que ver los periódicos y los accidentes que se producen de vez en cuando. Por favor, consideremos estos costes medioambientales y sociales también.
BIBLIOGRAFIA
https://www.arcweb.com/blog/machine-learning-adaption-predictive-maintenance-applications ARC advisory Group ARAMCO AND OTHERS
https://docs.aws.amazon.com/solutions/latest/predictive-maintenance-using-machine-learning/welcome.html AWS Solutions
https://spd.group/machine-learning/predictive-maintenance/ SPD Group Descripción sencilla del proceso y actores. IBM es uno de los grandes en sistemas de gestión de mantenimiento (propósito general—ordenes de mantenimiento, gestión stocks etc. MAXIMO)
https://rapidminer.com/glossary/machine-learning/ RAPIDMINER. Una de las herramientas para estudiar regresiones y patrones y construir el modelo.
Interesante definición de conceptos que a veces se tienden a confundir o solapar, dada su proximidad
No Comments